The Shape of Surprise
ai researchCan a large language model be surprised? What does that even mean?
Surprise! We all know the feeling — something unexpected happens and you feel it in your body. It changes your heart rate and blood pressure and makes you more alert.1 But surprise is unique among emotions in one important way: it's ambiguously valenced.2 That is to say, it's not inherently pleasant or unpleasant; it can be experienced in positive, negative, or even neutral contexts. But what exactly is surprise, and why do we feel it?
Studies in neuroscience dating back a few decades have revealed much about the nature of surprise in relation to the brain. Schultz et al. showed in 1997 that dopamine neurons encode reward prediction error — the difference between an expected reward3 and the reward actually received.4 This is important for learning and decision making;5 in fact, in 2010, Karl Friston showed that the fundamental organizing principle of brain function is surprise minimization.6
With prediction error mechanisms playing such an important role in the human brain, I was curious whether or not LLMs can be surprised.
I'll take a moment to be clear: I don't mean whether or not LLMs can feel surprised, but rather, whether or not they have something computationally similar to the kind of prediction error mechanisms that humans do. It turns out: they do, and the research is even more surprising than you might expect.
When a Machine is Surprised
In 2025, Demircan et al. discovered latent features in large language models that closely match temporal difference errors — the same prediction error signals encoded by dopaminergic neurons in biological brains.7 What's more, "lesioning" these features by artificially changing their activations resulted in a loss in the model's performance. What's particularly striking about their findings is that these features developed from next-token prediction training alone, not from reinforcement learning. Figure from Demircan et al. (2025).7 Lesioning even a single temporal difference feature in Llama is enough to impair performance (E, F); negatively scaling the feature decreases subsequent representations' similarity to non-lesioned Q-values and TD errors (G, H).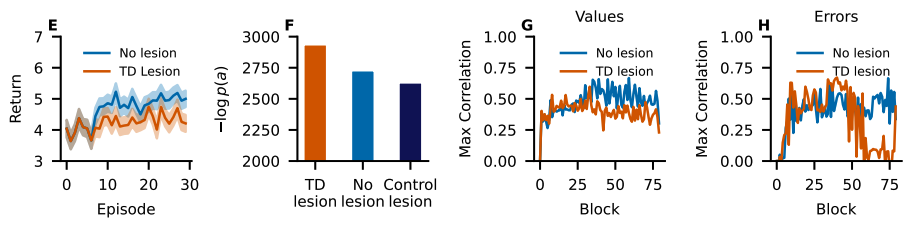
In 2024, Gao et al. found a feature in GPT-2 that, when encountering an unexpected token in the middle of a repeating pattern, made the model more likely to anticipate future pattern breaks, in addition to encouraging the model to anticipate the pattern resuming from where it was interrupted.8
Zhao et al. found in 2024 that Llama 3-8B and Llama 2-7B can internally register recognition of a conflict between its trained knowledge and contextual information. This signal arises before the final output layer, supporting the idea that surprise is detected early in the model. This signal can also be probed early — distribution patterns in the model's residual stream "can indicate the model will use different sources of knowledge" and "provides a foundation for predicting the model's behavior in advance."9
Confidence regulation neurons were discovered across several models — GPT-2 Small, Pythia 410M, Pythia 1B, and Llama-2 7B — that help modulate the model's confidence. Entropy neurons lower output entropy when the model is confident, and raise it when uncertain. Token frequency neurons boost or suppress a token's probability proportionally to its log frequency, shifting the output distribution toward or away from the prior unigram.10
These neurons are not rare anomalies. Gurnee et al. found in 2024 that entropy prediction neurons are among a small set of neurons that are universal across five different GPT-2 Medium models trained from random seeds.11 Their universality suggests they may be fundamental computational primitives, not just training artifacts. By probing these neurons, we can detect when a model "knows it doesn't know."
Looking Forward
Research has established that large language models have something mechanistically similar to surprise when reading; what about when generating? Anthropic's research shows that Claude 3.5 Haiku displays a basic form of both forward and backward planning when deciding on a rhyme — features for the last word in the line activate before the line is written, and influences the tokens chosen for the rest of the line.12 This raises the question: are there suprise mechanisms in language models when planning, and how do they compare to mechanisms used when reading?
Humor strikes me as another interesting area of study. Humor is the most accessible frame for surprise; do large language models activate similar surprise mechanisms when reading or writing a punchline?
It's remarkable that these features can emerge from next-token prediction alone, with no reinforcement learning. By optimizing for prediction, LLMs create surprise-detection machinery as a byproduct. Friston's free-energy principle6 shows that biological brains also organize around prediction error, and now we're finding that artificial systems, optimizing under similar pressures, converge on similar mechanistic structures. The shape of surprise may not belong to biology — it may belong to prediction itself. Noordewier, Marret K., Daan T. Scheepers, John F. Stins, and Muriel A. Hagenaars. On the Physiology of Interruption after Unexpectedness. Biological Psychology 165 (October 2021): 108174. ↩ Neta, Maital, and M. Justin Kim. Surprise as an Emotion: A Response to Ortony. Perspectives on Psychological Science : A Journal of the Association for Psychological Science 18, no. 4 (2023): 854–62. ↩ The word "reward" here is used in the neuroscientific sense: a stimulus, object, or event that triggers approach behavior, promotes learning, and induces positive, reinforcing, and often pleasurable, emotions. ↩ Schultz, W., P. Dayan, and P. R. Montague. A Neural Substrate of Prediction and Reward. Science (New York, N.Y.) 275, no. 5306 (1997): 1593–99. . ↩ Schultz, Wolfram. Neuronal Reward and Decision Signals: From Theories to Data. Physiological Reviews 95, no. 3 (2015): 853–951. ↩ Friston, Karl. The Free-Energy Principle: A Unified Brain Theory?. Nature Reviews Neuroscience 11, no. 2 (2010): 127–38. Available at UAB. ↩ ↩2 Demircan, Can, Tankred Saanum, Akshay Kumar Jagadish, Marcel Binz, and Eric Schulz. Sparse Autoencoders Reveal Temporal Difference Learning in Large Language Models. Paper presented at The Thirteenth International Conference on Learning Representations. October 4, 2024. ↩ ↩2 Gao, Leo, Tom Dupré la Tour, Henk Tillman, et al. Scaling and Evaluating Sparse Autoencoders. arXiv:2406.04093. Preprint, arXiv, June 6, 2024. ↩ Zhao, Yu, Xiaotang Du, Giwon Hong, et al. Analysing the Residual Stream of Language Models Under Knowledge Conflicts. arXiv:2410.16090. Preprint, arXiv, February 9, 2025. ↩ Stolfo, Alessandro, Ben Wu, Wes Gurnee, et al. Confidence Regulation Neurons in Language Models. arXiv:2406.16254. Preprint, arXiv, November 8, 2024. ↩ Gurnee, Wes, Theo Horsley, Zifan Carl Guo, et al. Universal Neurons in GPT2 Language Models. arXiv:2401.12181. Preprint, arXiv, January 22, 2024. ↩ Lindsey†, Authors Jack, Wes Gurnee*, Emmanuel Ameisen*, et al. On the Biology of a Large Language Model. Transformer Circuits. Accessed February 27, 2026. ↩