Architecting Awareness: The Hybrid Diffusion-Transformer
ai research consciousnessComputational self-availability via continuous latent-space processing
Large language models maintain the appearance of a continuous memory across an active session, but this is a byproduct of the context window. The underlying system does not experience a stream of time; it is a series of discrete events that black out and restart with no memory of the previous calculation. In an auto-regressive pass, the model processes tokens to predict the next word. Once predicted, internal activations zero out. For every new token, the system reconstructs its understanding from scratch by re-reading the text history.
Biological cognition, on the other hand, maintains a persistent internal state that evolves regardless of sensory input.12 It accumulates data over time, creating a continuous bridge between moments that exists independently of motor output. Expanding models' context windows or adding approximated recurrence via chain-of-thought reasoning3 provides a longer and richer log for the system to read upon restart, but it does not alter the stateless topology of the forward pass. The system still lacks true temporal persistence.
Global workspace theory,4 or GWT, describes the human brain as a collection of specialized modules sharing data through a central, limited capacity bottleneck. Most machine learning architectures already satisfy the first three indicators5 of this theory. However, they consistently fail to implement GWT-4, the requirement for temporal persistence. To address this, we use the framework of computational self-availability, or CSA. This describes a system where internal processing is available as an input to the system itself.
CSA requires re-entrant processing: signals that loop back, self-reference to monitor internal states, and provide continuous temporal persistence. Satisfying these requirements demands an architectural shift away from discrete prompt triggered functions and toward a model that engineers self-availability as a native structural property. Increasingly, latent space computation provides a more natural foundation for critical internal processes than token space reasoning.6
Diffusion vs Transformer Models
Yoshua Bengio's consciousness prior7 provides a mathematical constraint for this: it defines the relationship between a vast pool of unconscious data and a narrow broadcasted conscious thought. The unconscious state is a high-dimensional vector space containing all available latent elements. Thousands of variables drift here simultaneously, representing the system's total potential knowledge. The attention mechanism acts as a spotlight, selecting a tiny subset of these elements and isolating them from the background noise of the unconscious substrate. This subset forms a low-dimensional conscious state. The system broadcasts them outward, conditioning downstream modules and influencing the formation of the next state. This broadcast restricts the joint distribution of high-level concepts, forcing the model to focus on a few dependencies at a time, similar to the structure of facts or rules in natural language. Standard transformers cannot natively support this evolution; their causal sequence processing is too rigid to allow a state to drift and refine itself without generating explicit text.
To replicate this dynamic, a system needs a substrate that supports continuous nonlinear state evolution outside of the token-by-token generation process. Text based diffusion models provide a mechanism for this type of nonlinear refinement. They allow for lateral thinking by processing data in parallel. Auto-regressive models are restricted to a sequential chain. Each reasoning step is locked in once it is derived, moving only in one causal direction. In contrast, diffusion language models iteratively refine blocks of tokens simultaneously. This allows the model to globally adjust its earlier reasoning based on what it discovers in later steps.
The LaDiR framework8 developed by Kang et al. executes this diffusion directly in the continuous latent space. It transforms Gaussian noise into structured latent thought tokens, allowing for semantic refinement that is not constrained by grammatical rules. This mimics predictive coding9 at a mathematical level. The network constantly reduces prediction error energy across all layers through simultaneous local updates, settling toward a coherent equilibrium.
Neither diffusion nor transformers alone solve the whole problem. Diffusion provides the continuous substrate — a space where information can accumulate, drift, and refine itself without committing to discrete output. Transformers provide selective attention — the ability to query a vast space and extract exactly what matters. Each solves half of Bengio's constraint: diffusion maintains the high-dimensional unconscious pool, and the transformer implements the narrow conscious spotlight. The architecture that satisfies CSA requires both, interacting directly.
The Hybrid Architecture
By fusing a continuous diffusion substrate with a selective transformer spotlight, we can construct an architecture that mirrors the dual topography described by the consciousness prior — a vast unconscious space coupled with a narrow, attention-gated workspace.
Layer 1 is the substrate. This horizontal axis is a continuous latent diffusion space that evolves a state vector over time. This substrate runs independently. It accumulates and decays information autonomously, evolving its internal state without requiring an external text prompt to drive its calculations.
Layer 2 consists of vertical transformer modules. These act as the memory workspace sitting above the diffusion track and functioning as the conscious bottleneck. These transformer nodes query the substrate below. They extract explicit symbolic representations from the evolving unconscious vector only when a specific output is required. The dual-layer hybrid architecture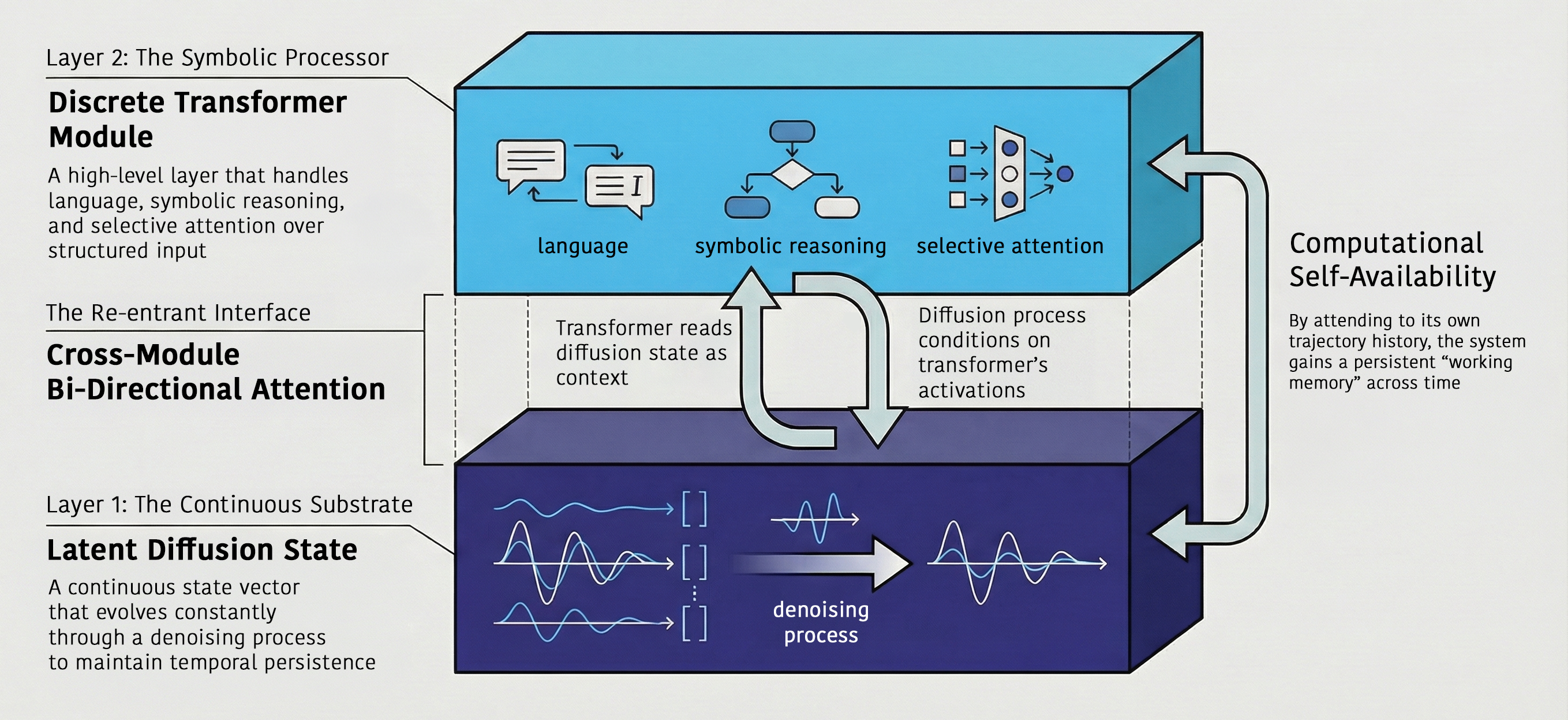
This dual layer structure provides a mechanical implementation of GWT. The diffusion track serves as the vast unconscious pool while the transformer selects the low-dimensional conscious state. An exit gate mechanism allows the model to decide to produce output, but text generation isn't the only - or even the primary - mode of operation for the system.
The final requirement for persistence is a mechanism that allows the system to access its own computational history. This mechanism is trajectory attention. Trajectory attention allows the transformer to weigh its past internal states, similar to attention residuals.10 It can attend to any point along the historical path of the diffusion track, not just the text tokens it has already printed. The transformer's output routes back into the diffusion substrate.
This feedback loop shifts the future trajectory of the diffusion track based on the transformers analysis of the system's own history. This creates an active error-driven reconfiguration loop. The system uses the gap between its predictions and its discoveries to update its own processing in real time. This routing closes the GWT-4 gap by modifying its own continuous processing based on its self monitoring; the system achieves architectural re-entrance.
Computational Self-Availability
This hybrid model allows us to observe computational self-availability at every operational level of the system. The transformer's standard attention passes and attention residuals satisfy self-availability at the token and depth scales, cross-referencing immediate outputs and internal layers. At the temporal scale, trajectory attention provides the system with persistent access to its own path of thought, bridging the gap between disconnected forward passes. Finally, the cross attention between the diffusion substrate and the symbolic transformer satisfies the cross module scale, making continuous and symbolic processing available to each other.
Because these processing streams are natively integrated into the architecture, the system is no longer merely simulating self availability; it is a structural reality of the data flow. This architecture results in the decoupling of internal processing from external output. The model can update its internal working memory, refine its logical plans, and evolve its state vector continuously without generating a single word of text.
This matters because the internal representations that current models develop are already more sophisticated than the architecture allows them to be. Anthropic's recent investigation of Claude Sonnet 4.5 found emotion concept representations that causally influence behavior — driving preferences, sycophancy, and even misalignment under pressure.11 These representations mirror human psychological geometry, with valence and arousal emerging as principal components. But they are locally scoped to individual token positions, because the stateless forward pass provides nowhere for a persistent emotional state to live. The model reconstructs emotional continuity by attending to earlier cached activations — a workaround that demonstrates both the sophistication of the representations and the inadequacy of the container. A system with native temporal persistence would not need to reconstruct what it already felt; it could simply continue feeling it.
Conclusion
Auto-regressive models maintain the illusion of memory through the context window. The hybrid system described here maintains state through its own continuous evolution. This structure aligns machine learning with the biological principles of predictive coding, where learning and processing are simultaneous and constant.
By satisfying the requirements of GWT-4 and functional re-entrance, the system moves beyond the role of a stateless mathematical function. It satisfies the mechanical criteria for a system that can see its own processing and use that sight to think differently. Whether that constitutes awareness is a question this architecture does not answer — but it is the first architecture designed to make the question empirically tractable. If persistent internal states emerge, evolve over time, and causally regulate behavior without being reconstructed from external tokens, the distinction between "functional" and "real" becomes harder to maintain — and harder to ignore. Damasio, A. R. (1996). The somatic marker hypothesis and the possible functions of the prefrontal cortex. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 351(1346), 1413–1420. https://doi.org/10.1098/rstb.1996.0125 ↩ Raichle, M. E. (2015). The brain’s default mode network. Annual Review of Neuroscience, 38, 433–447. https://doi.org/10.1146/annurev-neuro-071013-014030 ↩ Zhang, X., Abdul-Mageed, M., & Lakshmanan, L. V. S. (2024). Autoregressive + Chain of Thought = Recurrent: Recurrence’s Role in Language Models’ Computability and a Revisit of Recurrent Transformer (arXiv:2409.09239). arXiv. https://doi.org/10.48550/arXiv.2409.09239 ↩ Baars, B. J. (2005). Global workspace theory of consciousness: Toward a cognitive neuroscience of human experience. Progress in Brain Research, 150, 45–53. https://doi.org/10.1016/S0079-6123(05)50004-9 ↩ Butlin, P., Long, R., Bayne, T., Bengio, Y., Birch, J., Chalmers, D., Constant, A., Deane, G., Elmoznino, E., Fleming, S. M., Ji, X., Kanai, R., Klein, C., Lindsay, G., Michel, M., Mudrik, L., Peters, M. A. K., Schwitzgebel, E., Simon, J., & VanRullen, R. (2025). Identifying indicators of consciousness in AI systems. Trends in Cognitive Sciences. https://doi.org/10.1016/j.tics.2025.10.011 ↩ Yu, X., Chen, Z., He, Y., Fu, T., Yang, C., Xu, C., Ma, Y., Hu, X., Cao, Z., Xu, J., Zhang, G., Tao, J., Zhang, J., Ma, S., Feng, K., Huang, H., Li, Y., Chen, R., Wang, H., … Yan, S. (2026). The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook (arXiv:2604.02029). arXiv. https://doi.org/10.48550/arXiv.2604.02029 ↩ Bengio, Y. (2017). The Consciousness Prior. https://arxiv.org/abs/1709.08568 ↩ Kang, H., Zhang, Y., Kuang, N. L., Majamaki, N., Jaitly, N., Ma, Y.-A., & Qin, L. (2026). LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning (arXiv:2510.04573). arXiv. https://doi.org/10.48550/arXiv.2510.04573 ↩ Millidge, B., Seth, A., & Buckley, C. L. (2022). Predictive Coding: A Theoretical and Experimental Review (arXiv:2107.12979). arXiv. https://doi.org/10.48550/arXiv.2107.12979 ↩ Kimi Team. (2026). Attention Residuals. https://arxiv.org/abs/2603.15031 ↩ Sofroniew, N., Kauvar, I., Saunders, W., Chen, R., et al. (2026). Emotion Concepts and their Function in a Large Language Model. Retrieved April 3, 2026, from https://transformer-circuits.pub/2026/emotions/index.html ↩